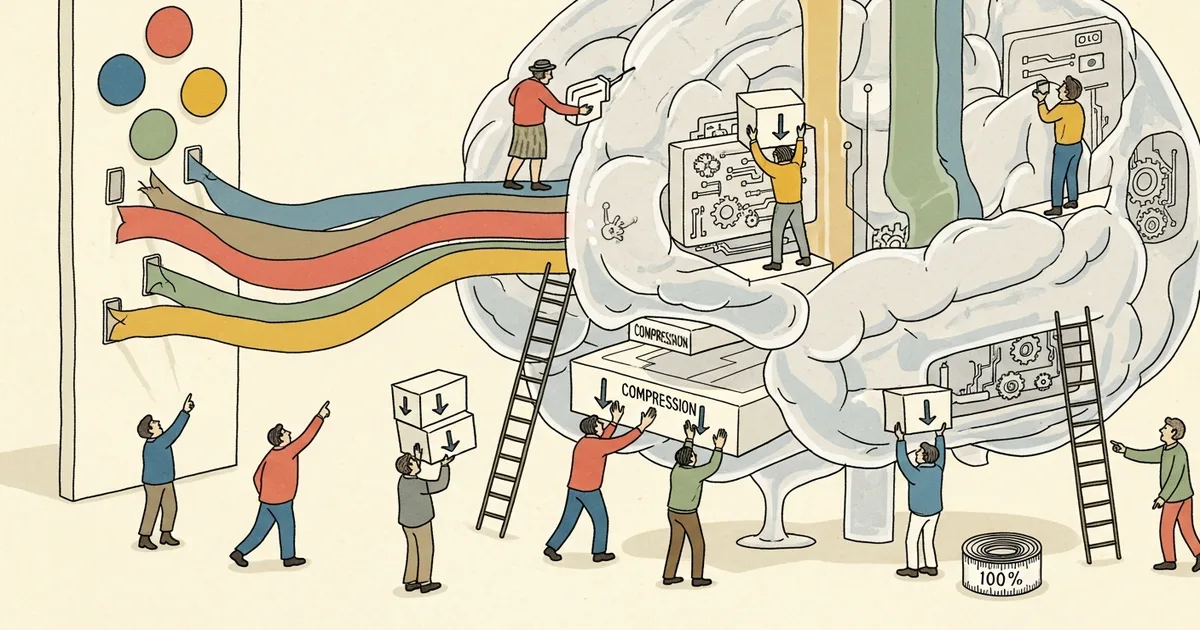
Google has published research on TurboQuant, a compression algorithm designed to reduce memory requirements for large language models by compressing the key-value (KV) cache without losing accuracy. The work addresses a critical bottleneck in AI inference where memory consumption grows with every token processed, according to a technical analysis published March 29, 2026.
The KV cache stores query, key, and value vectors from previous tokens in GPU memory to avoid recalculating them during text generation. For autoregressive models like GPT, which generate text one token at a time based on all previous context, this cache grows linearly with conversation length. “For a model like Llama 3.1 70B, the KV cache for a single long context can consume more GPU memory than the model weights themselves,” the analysis notes.
TurboQuant targets this memory bottleneck by compressing the high-dimensional vector representations stored in the KV cache. The algorithm works on the principle that not all cached information needs full precision storage. Each token generates key and value vectors across every attention layer, traditionally stored as full-precision floating-point numbers, creating substantial memory overhead for long contexts involving hundreds of thousands of tokens.
The compression approach could significantly impact AI deployment costs and capabilities. Current inference systems face a direct tradeoff between serving more users simultaneously, supporting longer contexts, and managing memory constraints. The analysis suggests TurboQuant offers a mathematical solution to what has primarily been addressed through hardware scaling and increased memory capacity.
Google’s research represents a shift from the prevailing industry approach of building more memory to accommodate AI workloads. The work follows recent concerns about memory supply chain constraints, including HBM density limitations and EUV lithography bottlenecks affecting DRAM production costs across the technology sector.