BENCHMARKS BullshitBench Results Show Anthropic Claude Models Dominate Top Seven Spots in Nonsense Detection Rankings 7/10 4 min read 2 months ago
GUIDES NIST AI 800-3 Introduces Statistical Models to Fix AI Benchmark Gaps 8/10 4 min read 2 months ago
BENCHMARKS Function Calling Harness Pushes Qwen From 6.75 Percent to 100 Percent Success on Complex Schemas 8/10 4 min read 2 months ago
BENCHMARKS Liquid AI Runs 24-Billion-Parameter Model at 50 Tokens Per Second in a Web Browser 7/10 2 min read 2 months ago
BENCHMARKS Open-Source ATLAS System on a $500 GPU Outperforms Claude Sonnet on Coding Benchmarks 7/10 2 min read 2 months ago
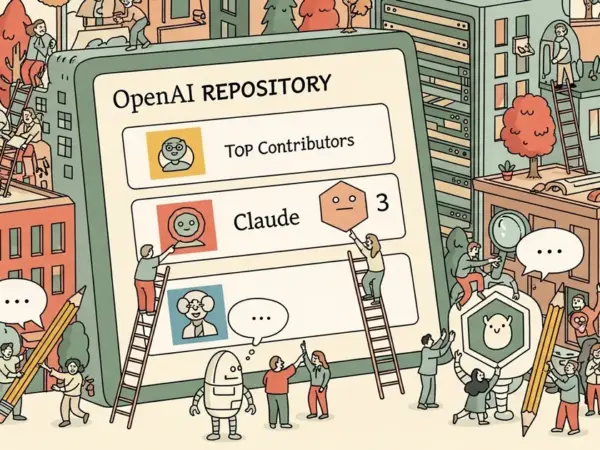
BENCHMARKS Claude Appears as Third Top Contributor on OpenAI Repository, Sparking Viral Debate 7/10 2 min read 2 months ago
BENCHMARKS Study Finds Hundreds of AI Benchmark Tests Are Fundamentally Flawed 8/10 4 min read 2 months ago
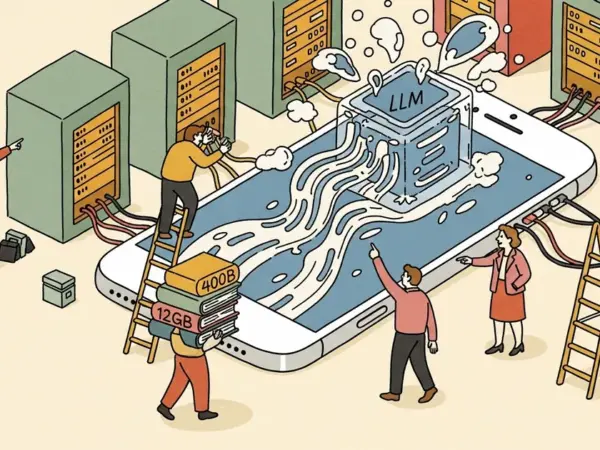
BENCHMARKS iPhone 17 Pro Demonstrated Running a 400-Billion-Parameter LLM with 12GB of RAM 7/10 2 min read 2 months ago
BENCHMARKS SWE-Rebench February Update: GPT-5.4 and Qwen3.5 Lead on Decontaminated Coding Tasks 8/10 4 min read 2 months ago
BENCHMARKS Mystery AI Model Suspected as DeepSeek V4 Revealed as Xiaomi’s 1-Trillion-Parameter MiMo-V2-Pro 7/10 2 min read 2 months ago
BENCHMARKS Benchmarks Show Vulkan Outperforms ROCm 7 for Short-Context LLM Inference on AMD MI50 7/10 4 min read 2 months ago
BENCHMARKS Humanity’s Last Exam Exposes the Gap Between AI Hype and Expert-Level Knowledge 8/10 2 min read 2 months ago