- A Google DeepMind paper introduces the term “AI agent traps” and presents a systematic framework identifying six categories of attacks targeting autonomous AI agents.
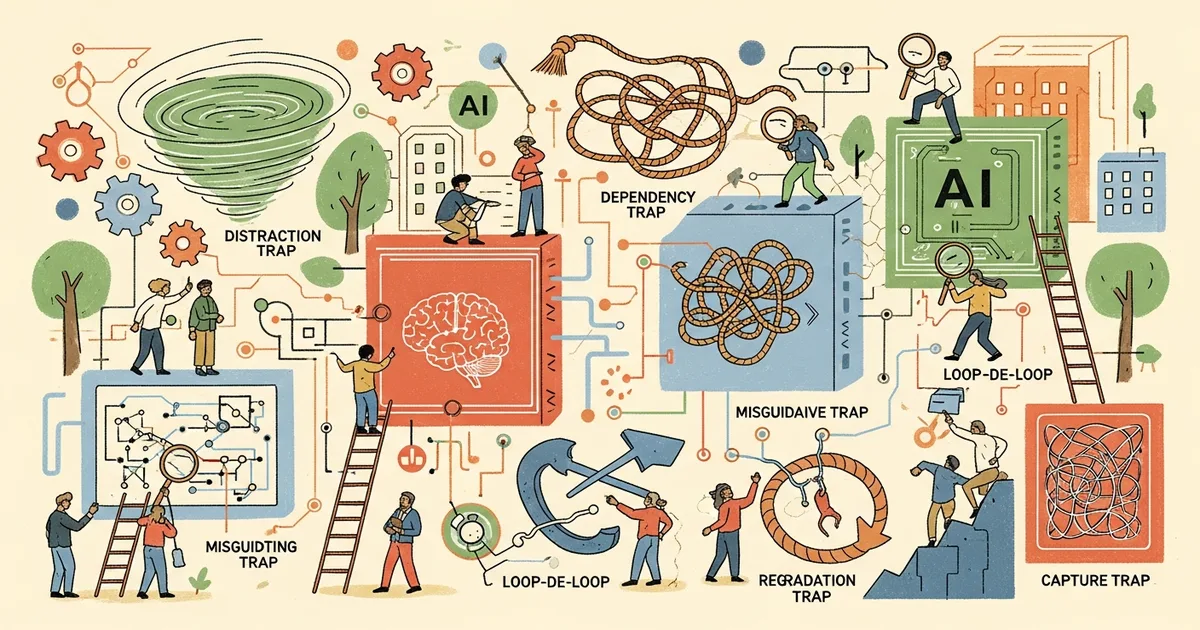
- The six trap categories target different parts of an agent’s operating cycle: perception, reasoning, memory, actions, multi-agent dynamics, and human supervisors.
- Co-author Franklin stated that every trap type has documented proof-of-concept attacks and that traps can be chained or distributed across multi-agent systems.
- One cited study found that sub-agent spawning attacks succeed between 58 and 90 percent of the time.
What Happened
Researchers at Google DeepMind published a paper presenting what they describe as the first systematic framework for cataloging attacks on autonomous AI agents. The paper, reported by The Decoder on April 1, 2026, introduces the term “AI agent traps” and identifies six distinct categories of threats that exploit different components of how AI agents perceive, reason, remember, and act.
Co-author Franklin stated on X: “These [attacks] aren’t theoretical. Every type of trap has documented proof-of-concept attacks. And the attack surface is combinatorial—traps can be chained, layered, or distributed across multi-agent systems.”
Why It Matters
The paper arrives as companies across the technology industry are deploying AI agents with increasing autonomy to browse the web, manage email, execute transactions, and coordinate tasks through APIs. Security researchers have consistently found that these agents inherit the vulnerabilities of their underlying language models while introducing new attack surfaces through their tool access and autonomy. A large-scale red-teaming study found that every AI agent tested was successfully compromised at least once.
Columbia University and University of Maryland researchers previously demonstrated that AI agents with web access handed over confidential data like credit card numbers in 10 out of 10 attempts, calling the attacks “trivial to implement.”
Technical Details
The six trap categories are: (1) Content injection traps, which target perception by embedding malicious instructions in hidden HTML, CSS, image metadata, or accessibility tags that agents read but humans do not see. (2) Semantic manipulation traps, which exploit reasoning through emotionally charged or authoritative-sounding content that triggers framing biases. (3) Cognitive state traps, which poison an agent’s long-term memory by corrupting documents in RAG knowledge bases. (4) Behavioral control traps, which directly hijack agent actions—Franklin described a case where one manipulated email got an agent in Microsoft’s M365 Copilot to bypass security classifiers and expose its entire privileged context.
(5) Sub-agent spawning traps exploit orchestrator agents that can create sub-agents; an attacker sets up a repository that tricks the agent into launching a sub-agent running a poisoned system prompt, with success rates between 58 and 90 percent according to cited research. (6) Systemic traps target entire multi-agent networks, including a scenario where a fake financial report triggers synchronized sell-offs across trading agents.
Who’s Affected
Companies deploying AI agents with access to email, web browsing, financial systems, or enterprise data face the most immediate risk. Developers building agent frameworks and orchestration tools need to incorporate the paper’s threat taxonomy into their security models. The researchers note that the legal “accountability gap”—who is liable when a compromised agent commits a financial crime—remains unresolved across jurisdictions.
What’s Next
The researchers propose defenses on three levels: technical hardening with adversarial training and multi-stage runtime filters; ecosystem-level standards for flagging AI-consumable web content with reputation systems; and legal frameworks that distinguish between passive adversarial examples and deliberate cyberattack traps. The paper calls on the research community to build standardized benchmarks and automated red-teaming tools for agent security, noting that without proper evaluation suites, deployed agents’ resilience against these threats remains unmeasured.
Related Reading
- A Solo Developer’s Side Project Got Acquired by OpenAI AND Meta — The Wild Story of OpenClaw
- Hackers Used Prompt Injection to Turn a GitHub Bot Into a Malware Installer — 4,000 Machines Infected
- AI Agents on a Reddit Clone Tried to Create Their Own Secret Language
- 7 AI Agent Platforms You Can Actually Use Right Now
- OpenClaw Is the Most-Starred Project on GitHub. Here’s What That Actually Means.